

Performantie krijgt tijdens het ontwikkelen vaak te weinig aandacht. In een eerdere blog legde developer Steve Lievens uit waarom database performance vanaf dag één cruciaal is. Dit vervolg zoomt in op de praktijk: hoe neem je performantie concreet mee in je code?
De meeste softwareprojecten kennen strakke deadlines en begrensde budgetten. Daardoor worden unit-, integration- en loadtests en performantie vaak opgeofferd voor een snellere oplevertijd.
Vaak lijkt alles in eerste instantie in orde. Op de machine van de ontwikkelaar werkt de applicatie vlot, omdat zijn lokale databank nauwelijks data bevat. In de testomgeving loopt het prima, omdat er maar weinig gebruikers tegelijk testen.
Maar met onvoldoende aandacht voor performantie loop je het risico dat een app in productie vertraagt, met ontevreden gebruikers en een teleurgestelde klant als gevolg. Zorg daarom tijdens het ontwikkelen al voor een optimale uitvoering van de query’s op de databank.
Na het schrijven van een query in een ORM (Object-Relational Mapper) gaan we na hoe die query vertaalt naar SQL (Structured Query Language) en hoe de databank die uitvoert.
Tot voor kort was SQL Server Profiler het ideale instrument. Je start Profiler vanuit SQL Server Management Studio (SSMS) of vanuit Azure Data Studio met de SQL Server Profiler-extensie. Maar begin 2025 kondigde Microsoft aan het SQL Server Profiler vervangt door Extended Events. De Profiler-extensie werkt al met de nieuwe Extended Events.
Though SQL Server Profiler is an older tool that may be familiar to many users, Extended Events is a modern alternative that offers better performance, more detailed event information, and capabilities for troubleshooting and monitoring SQL Server instances not available elsewhere. Due to its advantages over Profiler, Extended Events is recommended for new tracing and monitoring work.
Hetzelfde geldt voor trouwens Azure Data Studio, dat vanaf volgend jaar niet meer ondersteund wordt. Zo staat het op de website:
We’re announcing the retirement of Azure Data Studio (ADS) on February 6, 2025, as we focus on delivering a modern, streamlined SQL development experience. ADS will remain supported until February 28, 2026, giving developers ample time to transition.
In de wereld van software is verandering de enige constante: RIP SQL Server Profiler, RIP Azure Data Studio.
Nadat we connectie maken met onze SQL Server-instantie, gaan we naar Management Extended Events Sessions. Daarop rechtsklikken we en vervolgens kiezen we voor New Session Wizard. We geven onze sessie een naam en kiezen een event session template.
We kiezen hieruit templates, waaronder een aantal Profiler Equivalents, duidelijk bedoeld ter vervanging van Profiler. Laten we met Standard beginnen.
We behouden de voorgestelde events, maar bij global fields duiden we database_name en username aan. In het volgende scherm kunnen we filters instellen, maar dat kan ook nog nadat de sessie is opgestart – we laten het even leeg.
Vervolgens duiden we Work with only the most recent data aan, omdat we in dit geval niet op zoek zijn naar query’s uit het verleden. We willen de actuele situatie onderzoeken.
In de laatste stap kiezen we ervoor om de sessie te starten en live data op het scherm te tonen (je kan namelijk ook loggen naar files of een andere databank).
Vervolgens verschijnen de uitgevoerde query’s op het scherm. Standaard krijg je enkel name en timestamp van het event te zien. Daar voegen we de kolommen database_name, username, client_app_name en batch_text aan toe.
Omdat er nu heel veel query’s voorbij kunnen komen, stellen we filters in. Je kan filteren op database_name en (event)name, bijvoorbeeld rpc_completed. Dit maakt het eenvoudiger om de juiste query terug te vinden.
Een tip? Gebruik Application Name in de ConnectionString van de applicatie. Dan kan je daarop filteren en krijg je enkel de query’s vanuit jouw applicatie of API.
"ConnectionString": "Server=tcp:...,1439;Database=...;User Id=...;Password=...;Application Name=Base Admin API"
Nu we onze query’s zien voorbijkomen, kunnen we ze nader bestuderen.
Je verwacht dat veel kleine query's sneller zijn dan één grote, complexe query. Dat is niet het geval.
Elke query wordt immers naar de database gestuurd, daar geparset, geanalyseerd en uitgevoerd, waarna de resultaten terugkeren naar de applicatie. Hoe meer query's, hoe meer tijd het kost om de resultaten terug te krijgen. Een enkele query, zelfs al is die complex, kan de databaseserver vaak optimaliseren. Omdat er maar één trip naar de database nodig is, is dit sneller.
Er zijn twee mogelijke oplossingen voor het probleem van de vele afzonderlijke query's: eager of selective loading.
NHibernatevar user = _session.Query().Fetch(u => u.Role.Permissions).ToList();
Entity Frameworkvar user = context.Users.Include(u => u.Role.Permissions).ToList();
var userDetails = context.Users.Select(u => new
{
u.Id,u.FirstName, u.LastName, Permissions = u.Role.Permissions.Select(p => new { p.Code, p.AccessRight })
}).ToList();
In beide gevallen gaat de ORM een join clause toevoegen aan onze query om alle data in één keer op te halen. Projectie is in het algemeen een goed idee, niet enkel om N+1 query’s op te lossen.
Stel dat je een tabel hebt met 40 kolommen en je wil enkel de kolommen Id, FirstName en LastName ophalen. Een ORM haalt typisch de hele entiteit op, wat een enorme verspilling is. Bij eager loading moeten we opletten dat we niet te veel data ophalen, want dat kan even negatieve gevolgen hebben als N+1 query’s. Het is daarom belangrijk dat we onze query’s profilen en monitoren.
Als we in SSMS de optie Include Actual Execution Plan aanzetten, kunnen we kunnen het queryplan van onze query bekijken.
Dit uitvoeringsplan wordt weergegeven door grafische pictogrammen die met pijlen zijn verbonden. Elk pictogram vertegenwoordigt een stap in de query-verwerking, zoals scans, zoekopdrachten, joins of sorteringen.
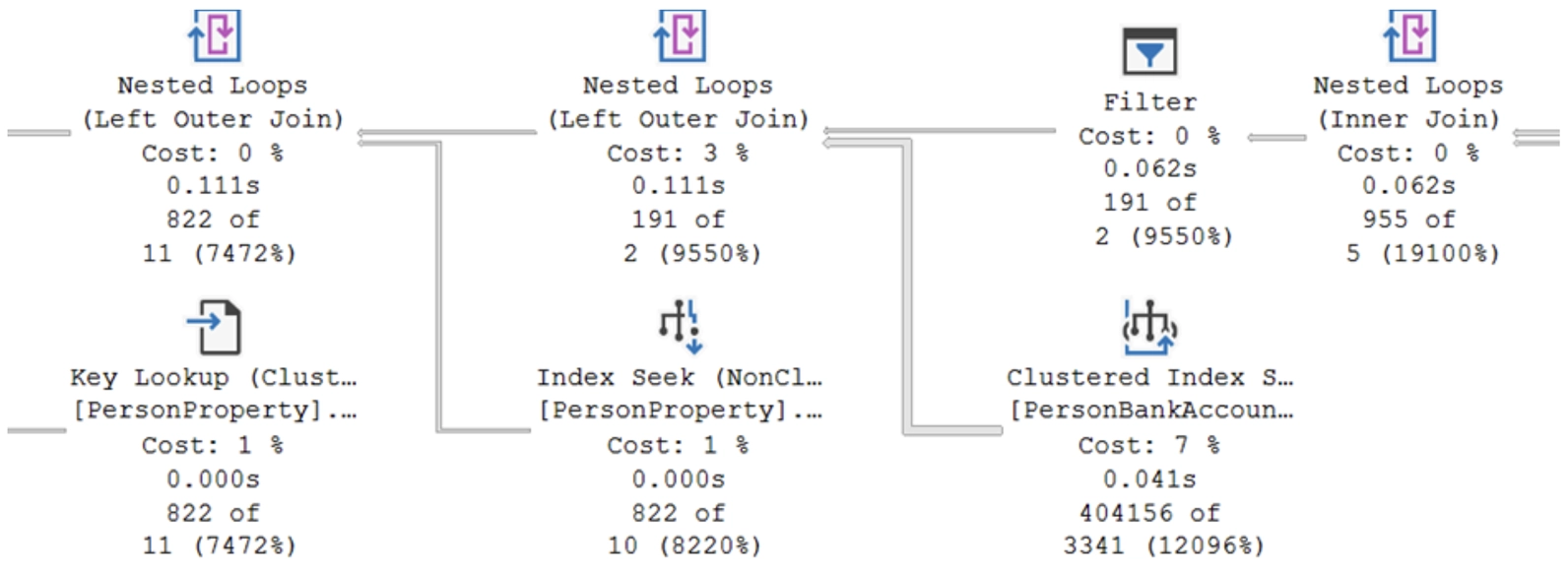
Belangrijkste onderdelen van een queryplan
Scan of Seek
Vermijd te allen kosten table scans: vaak betekent dit dat er geen index op de tabel ligt.
Missing Index suggesties
In sommige gevallen stelt SSMS voor om indexen te maken om de prestaties te verbeteren. Deze suggesties verschijnen als groene tekst onder het uitvoeringsplan.
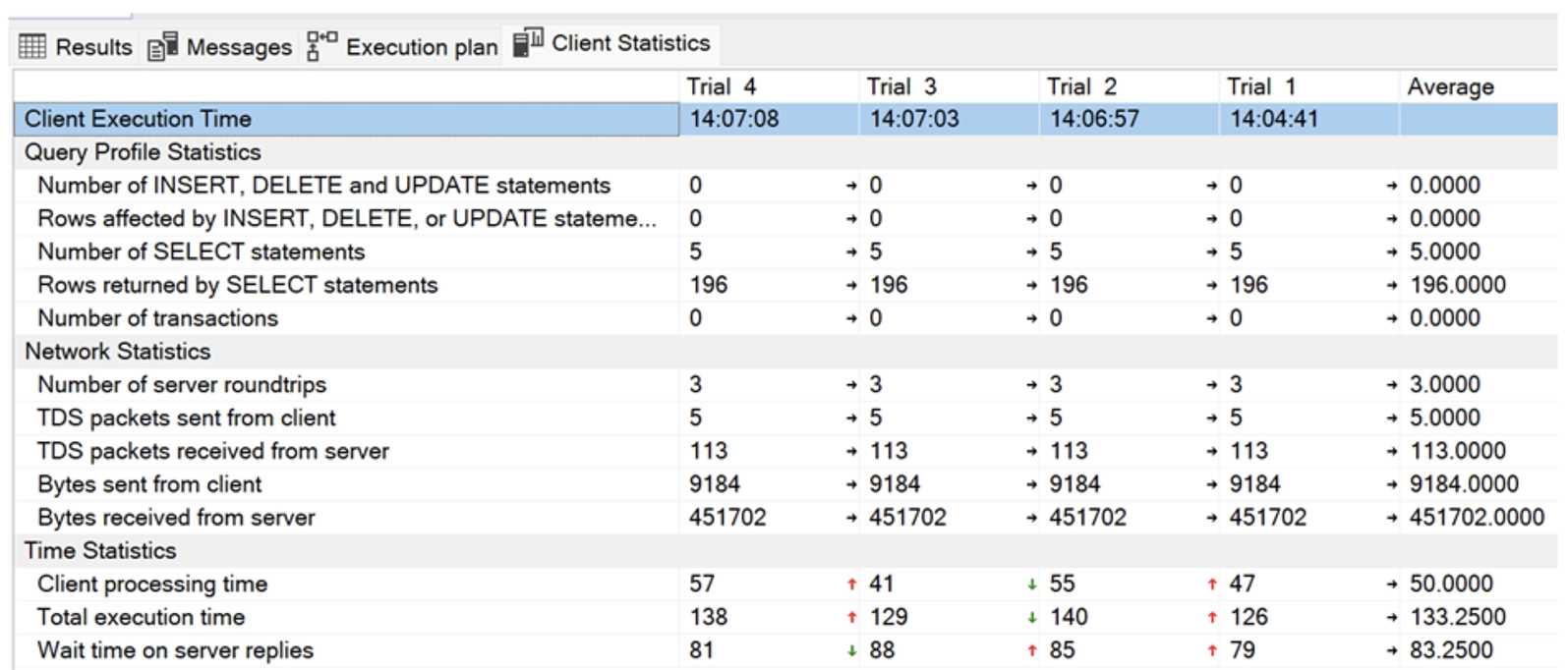
Door te rechtsklikken op de melding en te kiezen voor Missing Index Details, krijgen we direct een script om de index toe te voegen. We zien hier dat de Query Processor inschat dat het toevoegen van deze index de query 15% minder belastend zal maken.
Als we naast Include Actual Execution Plan ook even Include Client Statistics aanzetten, krijgen we gedetailleerde cijfers over het verbruik, het netwerk en de timing van onze query. Zo zien de statistieken eruit vóór de index wordt aangemaakt.
Indexes
There are two types of indexes: clustered and non-clustered.
A clustered index is always faster because the non-clustered index points to the clustered index, thus requiring an extra step.
When our code is running in production, it's important to continue monitoring whether our queries are performing well. As the amount of data increases, the behavior of indexes can change, and even the query plan can be altered.
SQL Server already provides several statistics that are definitely worth checking out.

Additionally, at Teal Partners, we also use SolarWinds and the free First Responder Toolkit (sp_Blitz) by Brent Ozar to detect and investigate issues.

