

Als softwareontwikkelaar is het nuttig om te blijven bijleren gedurende je carrière. Technologie verandert snel en de opkomst van AI heeft de techwereld op zijn kop gezet. Daarom schreef Kelly Hellinx van Teal Partners zich in voor de Master of Artificial Intelligence aan de KU Leuven. Zijn thesis gaat over het gebruik van Large Language Models in customer support.
Kelly Hellinx: “In een lijst met mogelijke onderwerpen van mijn promotor trok een vraag van DNS Belgium mijn aandacht. Dat bedrijf beheert de domeinnamen .be, .brussels en .vlaanderen. Het wilde onderzoeken hoe AI en Large Language Models, kortweg LLM's, toegepast kunnen worden in customer support. Dat sprak me aan, vooral omdat die kennis bij Teal Partners ook van pas kan komen, bijvoorbeeld in de payrollsoftware die we ontwikkelen.
Met mijn diploma in AI op zak en met de hulp van een stagiair gaan we nu bij Teal Partners concreet onderzoeken wat LLM’s voor onze klanten kunnen betekenen.
Kelly Hellinx: “Bij DNS Belgium komen veel supportvragen binnen, vaak over dezelfde topics. Het bedrijf wilde weten of een taalmodel bepaalde vragen automatisch kan beantwoorden, of een voorstel tot een antwoord kan formuleren. Ik maakte voor hen een proof of concept, gebaseerd op hun geanonimiseerde data. Ze bezorgden me duizenden supportvragen en bijbehorende antwoorden van de voorbije twee jaar. Vanwege privacyredenen wilden ze niet met ChatGPT werken, maar met een opensourcetaalmodel dat de data vertrouwelijk behandelt.”

Kelly Hellinx: “Een taalmodel rekent met woorden. Het kent een cijfer toe aan een woord. Via parameters worden verwante woorden aan elkaar gelinkt op basis van de kans dat ze samen voorkomen. Je kan een bestaand taalmodel verfijnen, m.a.w. aanpassen aan je eigen kennis. Aan de hand van duizenden reële supportvragen van DNS Belgium, en de bijbehorende antwoorden, ben ik een model gaan trainen. Zonder de juiste kennis gaat een model hallucineren. Het verzint een antwoord op je vraag, en dat klopt meestal niet. In customer support moet elk antwoord natuurlijk wel 100 procent juist zijn.”

“Maar het trainen van een model kost handenvol geld. Het vereist enorme computerpower en superkrachtige hardware. Bovendien: als de informatie wijzigt, of als er nieuwe vragen binnenkomen, of als er een nieuwe versie van het taalmodel is, dan moet je opnieuw trainen. Dat is in de praktijk niet haalbaar.”
Kelly Hellinx: “Met een techniek die RAG heet, Retrieval-Augmented Generation. Die combineert het genereren van teksten met het ophalen van informatie. Je laat het systeem eerst zoeken naar relevante informatie in specifieke bronnen, en die stuur je dan samen met de vraag naar het taalmodel. Het model gebruikt die informatie als context om een tekst te genereren. Het baseert zich dus niet alleen op de originele dataset waarmee het werd getraind, maar formuleert betere antwoorden dankzij die specifieke informatiebronnen.”

“De uitdaging is om correct te zoeken. Typisch wordt dat gedaan met keyword based search, bijvoorbeeld op het woord ‘domeinnaam’. Komt dat woord vaak voor in de tekst, dan is het waarschijnlijk een interessante bron.Maar zelfs als een zin sterk op een andere zin lijkt, kunnen ze nog totaal andere betekenissen hebben. Dezelfde woorden hebben meerdere betekenissen, zoals ‘bank’. Of door het toevoegen van het woord ‘niet’ krijgt een zin een tegengestelde inhoud. Daarom is er nog een tweede zoektechniek, met name semantisch zoeken, gebaseerd op tekstfragmenten. Je zet de betekenis van een tekststukje om in getallen. Komt de betekenis overeen met de informatie in je kennisdomein, dan is die bron waarschijnlijk relevant. Die ga je voeden aan je taalmodel.”

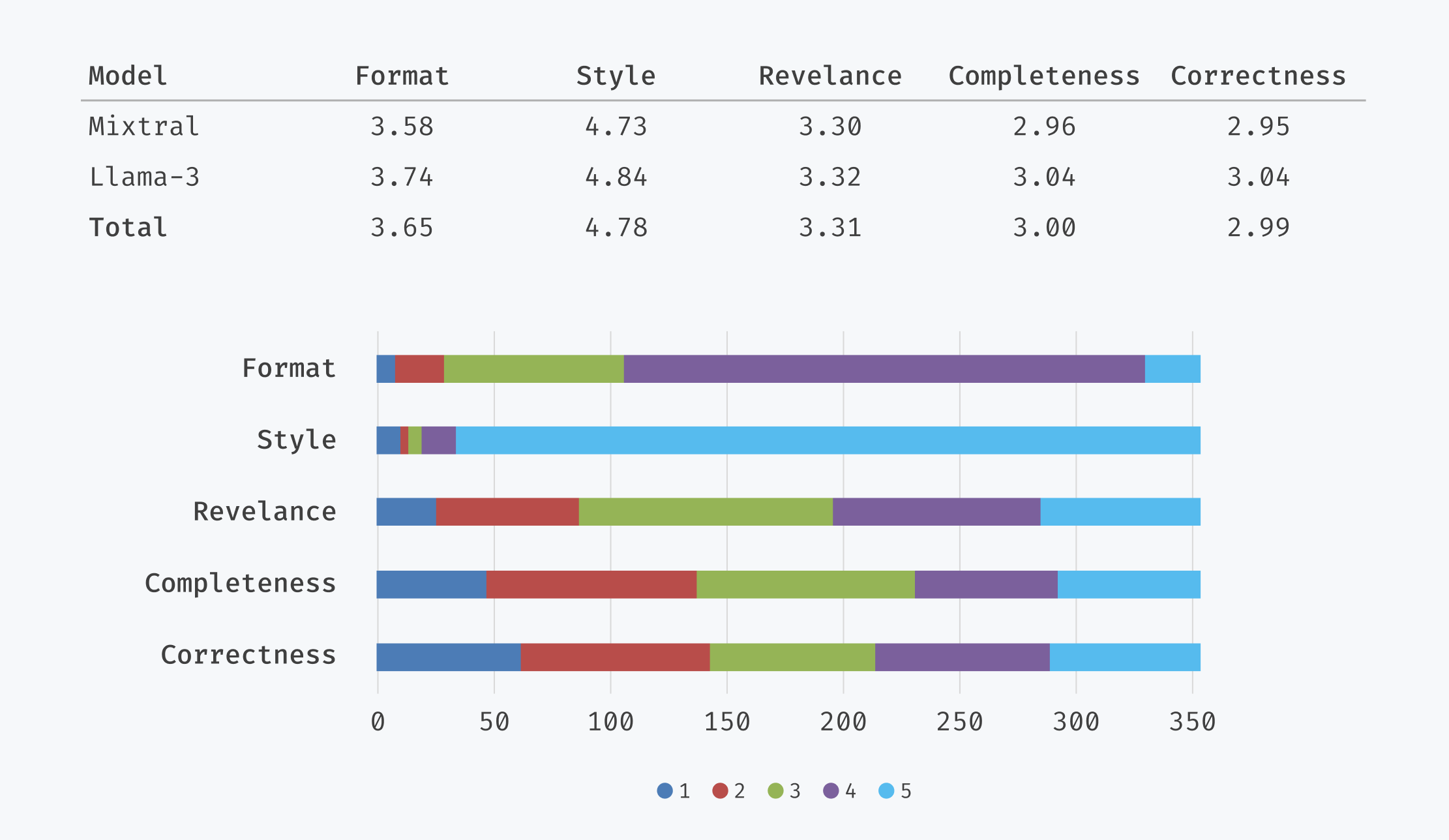
Kelly Hellinx: “Mijn onderzoek bewijst dat LLM’s kunnen helpen bij customer support. Maar het model dat ik heb gebouwd is nog niet klaar om ingeplugd te worden. Het moet verder verfijnd worden. Zeshonderd antwoorden van het taalmodel zijn geëvalueerd door een customer support-verantwoordelijke bij DNS Belgium. Hij beoordeelde het formaat, de schrijfstijl, de relevantie, de volledigheid en de juistheid van het antwoord met een score tussen 1 en 5. Formaat en stijl bleken prima, maar de relevantie van de antwoorden moet nog verbeteren door het model verder te trainen.”
Kelly Hellinx: “AI zit op de piek van zijn populariteit. Er gaan miljarden dollars in om. Veel bedrijven willen ‘iets met AI’ doen, maar wat? Ze tasten in het duister. Het is niet evident om een zinvolle toepassing te vinden. Wat maakt het werk efficiënter? Hoe help je klanten met AI? Hoe benut je het commercieel? Na de hype komt weldra de ontnuchtering. Je moet de juiste knowhow hebben en de investering is hoog. Hoe ga je de juistheid van je resultaten voor klanten controleren? Wat zijn de ethische implicaties? Er zijn nog veel vragen te beantwoorden. Gartner deed interessant onderzoek naar de hype rond AI.”
Kelly Hellinx: “Met mijn diploma op zak en met de hulp van een stagiair gaan we bij Teal Partners heel gericht onderzoeken wat AI en LLM’s kunnen betekenen voor onze klanten. We willen een proof of concept ontwikkelen om te ontdekken wat er bijvoorbeeld zinvol in onze payrollsoftware kan worden geïntegreerd. Kan AI ons helpen om veelvoorkomende vragen van gebruikers te beantwoorden? Dat is een eerste concrete toepassing die we verder willen onderzoeken.”
LLM’s, RAG, parameters en modellen: niet-ingewijden horen het vaak in Keulen donderen als het over AI gaat. Wie kan ons beter inwijden dan ChatGPT itself? Vier eenvoudige vragen, verklaard door het populairste taalmodel van het moment.
Een LLM begrijpt en genereert teksten. Het baseert zijn antwoorden op de patronen van teksten die het heeft geleerd via machine learning. Het model wordt gevoed met miljarden woorden en zinnen uit diverse teksten, waardoor het de structuur van taal leert begrijpen. Een LLM voorspelt de tekst die hoogstwaarschijnlijk volgt, gebaseerd op wat het heeft geleerd.
De bekendste modellen zijn GPT van OpenAI, maar ook LLaMa van Meta, en Google’s modellen Bert, T5 of PaLM. Er zijn ook opensourcemodellen, zoals BLOOM. Veel bedrijven en onderzoeksinstituten bouwen nu hun eigen modellen, wat bijzonder duur is.
Een LLM bevat miljoenen tot miljarden parameters. Een parameter is een gewicht dat bepaalt hoe sterk de relatie is tussen bepaalde woorden. Het model zet woorden om in getallen die door een neuraal computernetwerk worden verwerkt, en leert de verbanden tussen de numerieke representaties van die woorden. Een kleiner model heeft minder parameters en is daardoor minder nauwkeurig. Het trainen van een model kost tienduizenden euro’s voor een klein taalmodel en loopt op in de miljoenen voor de grotere modellen.
Het AI-systeem zoekt eerst in een specifieke database naar relevante informatie. Het gebruikt die informatie als context om een tekst te genereren. Hierdoor is het model niet beperkt tot wat het heeft geleerd tijdens zijn trainingsperiode, maar kan het ook actuele of domeinspecifieke informatie gebruiken.

